
|
Fig. 2
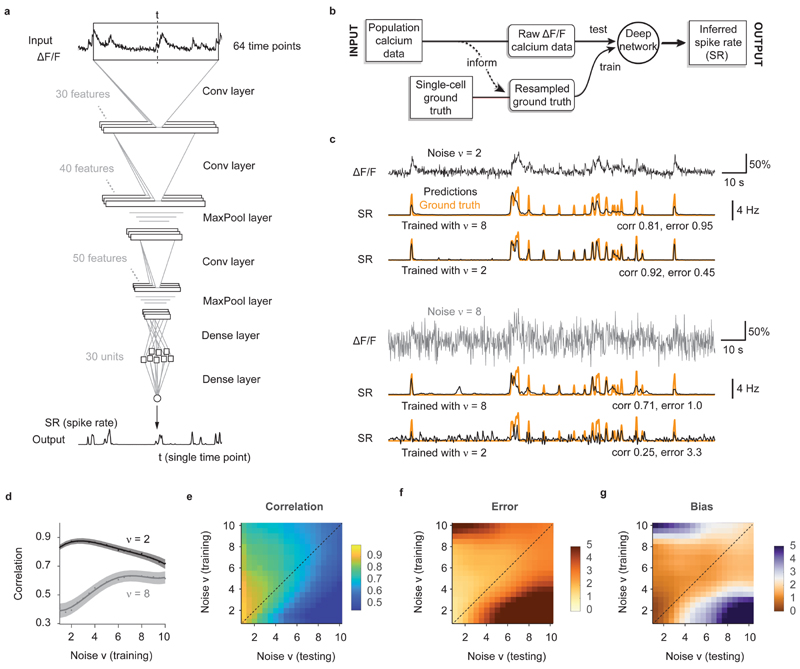
a, The default deep network consists of an input time window of 64 time points centered around the time point of interest. Through three convolutional layers, two pooling layers and one small dense layer, the spiking probability is extracted from the input time window and returned as a single number for each time point. b, Properties of the population data (frame rate, noise level; dashed line) are extracted and used for noise-matched resampling of existing ground truth datasets. The resampled ground truth is used to train the algorithm, resulting in calibrated spike inference of the population imaging data. c, Top: a low-noise ΔF/F trace is translated into spike rates (SR; inferred spike rates in black, ground truth in orange) more precisely when low-noise ground truth has been used for training. Bottom: a high-noise ΔF/F trace is translated into spike rates (SR; inferred spike rates in black, ground truth in orange) more precisely when high-noise ground truth has been used for training. v in units of standardized noise, % · Hz −1/2. d, The spike inference performance for two test conditions (low noise, v = 2, dark gray; high noise, v = 8, light gray) is optimal when training noise approximates testing noise levels. e, Correlation between predictions and ground truth is maximized if noise levels of training datasets match noise levels of testing sets. f, Relative error of predictions with respect to ground truth. g, Relative bias of predictions with respect to ground truth. Column-wise normalized versions of (e-g) are shown in Extended Data Fig. 3.